The license granted hereunder will terminate [...] if you [...] initiate [...]
any Patent Assertion: (i) against Facebook or any of its subsidiaries or corporate
affiliates, (ii) against any party if such Patent Assertion arises in whole or
in part from any software, technology, product or service of Facebook or any of
its subsidiaries or corporate affiliates, or (iii) against any party relating
to the Software.
---
Not a lawyer, but I would guess that's makes it a non-starter for many situations. You sue them, now your customers' data, your code repository, or backups have to be decoded with a software for which don't have a license to use anymore. Am I crazy, and this is not a BigDeal(TM)? Or does anyone else have an issue with this?
Patents are separate from copyright licenses. If you find some source code licensed under GPLv2, MIT, BSD, and many other OSS licenses, then these come with no patent license. It is up to you to find out if any patents covering them exist (by original authors or anyone else), and negotiate a patent license. Or if you live in a country that does not recognise software patents, you can just ignore the issue.
So an explicit patent grant, even if terminated if you sue Facebook for patent infringement, is much better than omitting the PATENTS file.
The very popular OSS Apache 2.0 license includes the same language to grant a patent license that is terminated if you start a patent lawsuit. Avoid suing Google about Android patents or Microsoft about .NET patents if you are using that software.
Overall I think it's a good thing, and if enough open-source projects adopt the same rule, then it could perhaps become a poison pill that stops everyone from enforcing software patents.
I agree with your concerns. This seems to be standard for Facebook.
I saw a similar grant for React js project [1]. The wording has had me look at alternatives for commercial use. The patent grant in React has been on HN several times in the past [2]
Facebook has an Open Source License FAQ where the explicitly do NOT mention the scenario you mention. [3]
This is standard for Facebook open source. Keep complaining though, they've made adjustments in the past (it used to be worse?) due to these types of concerns being raised.
Prior to being into Facebook's GitHub, it was into a Yann's GitHub, with different license terms. Someone could fork it, keeping the compatibility with the latest API. It could be enough for FB being pragmatic and releasing it under a more permissive license (in my opinion they should, making wider adoption easier).
Apache2 seems to be talking only about suing regarding the patent related to the work in question:
> such license applies only to those patent claims licensable by such Contributor that are necessarily infringed by their Contribution(s) alone or by combination of their Contribution(s) with the Work to which such Contribution(s) was submitted.
Facebook's version applies if you sue Facebook for any patent assertion.
Say you have a startup in talks to being bought by Google. The are suing Facebook because Facebook stole their ad click fraud detection algorithm. Now they'd be an additional worry about that patent claim.
Good question. I can see two interpretation (but IANAL so am probably very wrong here):
1) BSD license covers copyright, and that patent file covers patent grants. Totally separate things. If you sue Facebook, you retain the BSD license and they can't sue you back for copyright infringement, but they can then come after you asserting you infringed their compression patents and demand royalties.
2) Because PATENTS file says "Additional Grant of Patent Rights Version 2" it could mean an extension of the BSD license. That is the termination would trigger the revocation of copyright license as well not just patent protection.
The BSD license allows adding more restrictions. That's why people like it, because it allows you to remove freedoms; or rather, they dislike copyleft because it does not allow adding further restrictions.
I don't know what are the consequences of the Facebook patent clause, but I know the BSD license doesn't contradict it.
The BSD license states "Redistribution and use in source and binary forms, with or without modification,
are permitted provided that the following conditions are met: ...". If facebook is distributing their project under that license, and the terms are followed, then any lawsuit that facebook files against you for redistribution or use of the binary or source forms should be covered by promissory estoppel. I can't see how patents would change that. IANAL, though.
I think patents on software are almost immoral, and I will freely promise, under any penalty you can think of, to never sue anyone for software patent infringement.
So no, this is just another one where once or twice a year someone reads that license and tries to make it a "BugDeal".
I've been completely impressed with zStandard. I tested it when 1.0 was released, and I was blown away by both its performance and compression ratio, especially on multi-core machines. I'm using it in a project at work (prototype stage at the moment) and I'm confident we'll ship with zStandard as the default compression method.
We're aware of the potential license issues, but not concerned they'll be a problem (for now).
Also, in my system all compressed data is marked with its compression type, so it's possible for me to later find zStandard-compressed data and recompress with a different algorithm if needed. It would be a lengthy process, but at least possible.
If you control both sides of the channel - compression and decompression - and can make money out of better or faster compression, you should definitely look into RAD Game Tools' Oodle libraries - they exceed LZ4/Zstd on all axes.
What's the memory footprint for Zstandard (vs. zlib) for compression and decompression?
The article goes into CPU usage (which seems awesome...) but I don't see anything about the buffer sizes for either. It just mentions them as knobs that can be twiddled.
The table mapping compression levels to window sizes is at https://github.com/facebook/zstd/blob/15a7a99653c78a57d1ccbf.... The first element is the window size. I'm pretty sure you raise 2 to that power to get the window size. As you can see, level 1 is 2^18, which is 256KB - far larger than the minimum of 1KB. Lowering it will make compression faster at the expense of compression ratio.
For comparison, zlib's max window size is 32KB. That's one reason its compression ratio is so limited.
Ask HN: What is the best approach to compressing ProtoBuf streams? Does it still depend completely on the content being serialized, even with the ProtoBuf metadata?
For example: brotli is designed with an existing dictionary optimized for HTTP. Based on this design decision, it seems like it wouldn't necessarily be a good idea to use it with ProtoBuf, especially for small ProtoBuf serialized plain-old-[whatever]-objects in a data access layer.
Poking around a bit so far, it seems http://blosc.org/blosc-in-depth.html may be the right choice, but I'm not so sure about adopting its serialization stuff since it isn't as widely xplat as ProtoBuf.
If your decision was obvious after reviewing multiple algorithms then you might save me some time by sharing your experience; thanks in advance!
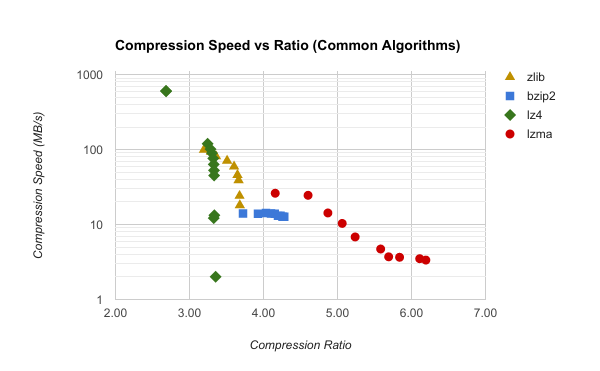
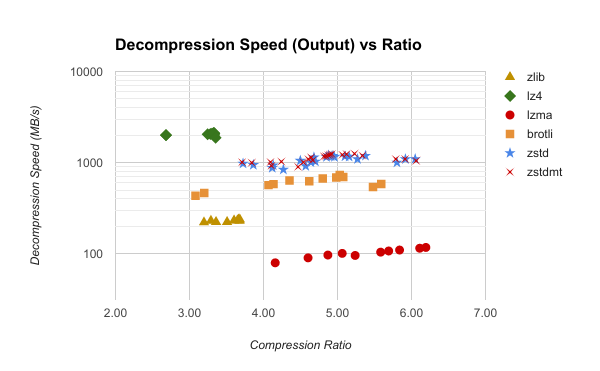
This is great. But please note, some of the graphs presented use a common statistics cheat of logarithmic scale along one or more of the axis.
Many times, lz4 level 1 isn't just 25% faster [0] in Compression vs. say zlib level 1 (as it appears visually), it's actually 6 times (6x, or 600%) faster in terms of MB/s (~600 MB/s vs. ~100 MB/s)!
And it's not just 5% or so faster than zstd in Decompression (visually) [1], it's about twice as fast (~2000 MB/s vs. ~1000 MB/s).
Yes. It does not compress as well. But ~3.2:1 compression ratio best case for lz4 (listed as ~3.2 in the chart) compresses almost as quickly as the 6:1 zstd [0] but will then decompress twice as fast as zstd at any level [1]. Having a high-compression is a case I could (almost) not care about. If you're youtube/google or facebook/instagram, you might care (streaming, photos, static assets all at enormous scales).
For me, however, the above results mean far less CPU burden on the client with a twice the burden on the network I/O. If you're concerned about battery, loading screens, or download dialogs, I'd still pick lz4. Just turn the AC up a half notch in my AWS DC.
Zstandard is awesome technology but I do not like the name. It is like those ad jingles that change 2 notes from a hit song chord to avoid paying royalties.
I've been very impressed with zstandard in general, on x86, and satisfied with it on other architectures. It seems to do a good job and do it well.
About the main reason I haven't pushed on using it for work is just concerns about maturity. gzip/pigz works well enough for our purposes, and isn't enough of a hindrance to justify using what is still new software without a proven history.
I definitely understand reluctance to trust new data formats. I will say though that we have been using Zstandard in production at Facebook since well before 1.0 and trust it completely for both data at rest and data in flight. Since 1.0, we've widened that even further to many different parts of the company.
To that end, every release (and pretty much every commit) undergoes significant testing. We also fuzz test heavily and have significant regression tests in place constantly looking at corner cases and verifying known prior bugs stay fixed. It's impossible to prove there are no issues, but so far we've put a lot of effort into being as reliable as possible and seen that play out well in our production environments. We trust it.
I just like to be careful with a mental "new tech" budget for a project/platform. The more new tech is involved, the more risk there is. The balancing point there being the value the new tech brings.
With the platform I'm working on at the moment, the gains are relatively minor: shaving a few seconds off here and there, when things are in the scale of minutes; and saving 20-30MB when things are in the scale of gigabytes, but also not lots of them. As the project grows, and as the new tech we've introduced proves itself, there's always scope to introduce other new tech like Zstandard and start gaining in the storage savings.
Are there any negatives to Zstandard (besides those listed in the article)? Specifically, I was thinking about using it to compress backup archives. I figure it might be annoying to use an algorithm that can't be extracted using default installed tools (though zstd is in Ubuntu 16.10 repos), but otherwise I don't see any downside.
The PATENTS file. Calling it "zstandard" is a genius move - everyone assumes it's a replacement for zlib (royalty free, bsd-style copyright, patent free), where only the first two are in fact right.
Standard tooling can be a big deal for some use cases. Having your data compressed with zlib means that you can stream it without decompressing to a client that can handle zlib streams.
The biggest candidate for that is serving static assets to browsers which can natively decompress a zlib compressed response by checking the response Content-Encoding.
Until browsers catch up, you'd have to either serve uncompressed traffic to the end user or recompress it for transport (which kind of kills the whole point right?).
You usually get a tiny bit better compression with .xz, but it's much slower. So in scenarios where compression speed is mostly irrelevant and you only care about size, take .xz. Otherwise zstd is usually the best choice.
I've hit a few problems using zstd from an early version (0.01?) - compressed files created by the original tools were not de-compressible using more recent programs :(
I think the problem lies in the perl library Compress::Zstandard, rather than in the zstd code itself. The C code has flags to enable 'legacy' support and they they are on by default. The perl library doesn't seem to be using them...
When I get the time, hopefully I can track this down further and submit a patch if this turns out to be the case.
Last week I needed to compress some large CSV files (70+ MB) and tested some compression algorithms for speed/ratio and was surprised that bzip2 was (in this isolated case) way better than Zstandard. Zstandard needed a lot more time (bzip2 3s vs Zstd 15s) to reach the same compression ratio and produced noticeably larger files (5 MB vs 6.2 MB) in its default configuration.
So Zstandard is not the compression algorithm to end them all and definitely has its weak spots.
bzip2 is BWT-based and Zstandard is based on Lempel-Ziv. They are fundamentally different algorithms and each algorithm has its sweet spot in terms of input data. BWT sorts, so it benefits from sorting-friendly data. LZ benefits from long repeats.
The problem with PPM is that it's slow. Zstd is targeting a certain general-purpose use case. There are other compressors that target different time-space trade-offs, if you need extreme performance or extreme compression efficiency.
The conclusion is not radical but quite banal. For some data, zstd (and lzma) lose to methods more suitable to that kind of data. For example, for text, use ppmd.
Using bzip2 is not a great idea because it's old, you can always beat it using newer methods. But bzip2 is widely installed, so that makes it somewhat useful.
The OP also shows zstd being very close to lzma for high compression ratio jobs. In my experience, for higher compression ratios lzma handily beats zstd (in the pareto-optimal sense of the word). But lzma is slow to decompress. If decompression speed matters a lot, zstd is awesome.
If you need to compress something like game assets (compression speed doesn't matter, compression ratio matters, decompression speed matters a lot) and can afford to use proprietary code then check out Oodle [1]. It beats zstd.
Potentially interesting for use with ZFS as an LZ4 alternative?
I recently did some benchmarking with lz4, gzip-6 and gzip-9 to look at using better compression for archival datasets. However, the overhead of gzip made the system largely unresponsive for days! An algorithm with better compression ratios but less CPU overhead would be a great addition.
We currently are exploring a seekable format for Zstandard right now. What use case do you have in mind -- network or at rest? If you want to file a github PR describing how you'd like it to work, that will help guide our implementation. We have a few in mind based on internal Facebook use cases, but the more different needs we know about, the more general purpose the result will be.
I have always thought that the 7-Zip format is interesting in the way it (or the reference implementation of the compressor, at least) groups files by extension, which I guess helps compression by making it more likely that chunks of files that are common within a filetype end up in the dictionary before it fills up with chunks from all filetypes. Do you have any thoughts about this? Have you looked at the 7-Zip format?
That's cool, thanks for sharing. I actually meant to ask the OP if they had looked at the 7-Zip format when designing their own archive format, but maybe they don't need to...
{kind=link}
{kind=link}
However this worries me:
https://github.com/facebook/zstd/blob/dev/PATENTS
---
The license granted hereunder will terminate [...] if you [...] initiate [...] any Patent Assertion: (i) against Facebook or any of its subsidiaries or corporate affiliates, (ii) against any party if such Patent Assertion arises in whole or in part from any software, technology, product or service of Facebook or any of its subsidiaries or corporate affiliates, or (iii) against any party relating to the Software.
---
Not a lawyer, but I would guess that's makes it a non-starter for many situations. You sue them, now your customers' data, your code repository, or backups have to be decoded with a software for which don't have a license to use anymore. Am I crazy, and this is not a BigDeal(TM)? Or does anyone else have an issue with this?