>The equations that do autocorrelation are computationally exhaustive: for every one point of autocorrelation (each line on the chart above, right), it might’ve been necessary for Hildebrand to do something like 500 summations of multiply-adds...
>Hildebrand realized he was limited by the technology, and instead of giving up, he found a way to work within it using math. “I realized that most of the arithmetic was redundant, and could be simplified,” he says. “My simplification changed a million multiply adds into just four. It was a trick — a mathematical trick.”
I would like to see them dramatize Dijkstra's algorithm in the same style. Instead of looking at all possible paths of arbitrary length within the graph, of which there are infinitely many, ...
My (very non-expert) reading of the patent is that it uses sample reduction and some specific features of the periodic form of the human voice to simplify the math involved in the auto-correlation routine. Although this routine does seem to be unique as far as I know, I wouldn't be surprised if it shares similarities to other techniques to reduce correlation complexity.
> “I realized that most of the arithmetic was redundant, and could be simplified,” he says. “My simplification changed a million multiply adds into just four.”
at the era of deep learning, no one is impressed by their 500 summations of multiply adds, or 1 million multiply adds.
A geforce 1080ti does 11.3 TFlops, with a T, that's 11 300 000 000 000 floating point operations per second..
In 1996 your processor might be running at 150MHz. Using a standard 44.1kHz sampling rate, that doesn't give you very many cycles to get each sample processed to do this in real time.
That's fine, but being able to run multiple audio tracks worth of VST plugins in real time on a modest laptop is very likely more valuable to their target market
You'd be surprised how quickly those 500 multiply-accumulates per autocorrelation point add up... a 128-tap filter * 500MAC/point * 2 channels(stereo) * 192ksps is already at 24+billion FLOPS for a single track...
CPU usage is even more of a problem that several years ago. Some very well known _compressors_ takes a whole 10% of CPU here. 10 of them and you're not realtime, probably earlier than that.
It's worth mentioning that even if Auto-Tune has pioneered the field and is now almost a mainstream househould name (much like Photoshop), nowadays all the cool kids are on Melodyne, which is frankly black magic : https://www.youtube.com/watch?v=9FScFKuXXM0
Oh dear, this guy has no limit to his self-aggrandizement, and the interviewer surely does very little to fact-check his outrageous statements. The facts are more like: auto-tune is the combination of pitch detection and pitch shifting, two problems that were extensively researched already. Even the details, like using autocorrelation via FFT, was standard in the field at the time. This type of pitch correction had already been done in academia, but passed off as a curiosity. The truth is, the guy was at the right place at the right time, nothing more than that. Computers were just becoming fast and cheap enough, and plugin formats making this type of product practical were just being deployed.
Detecting pitch may be easy enough, but a lot of programs still seem to have trouble adjusting pitch transparently without weird artifacts (without simply changing the speed). That's something Auto-Tune does seem to manage better than most.
Well there's a huge difference between monophonic and polyphonic pitch shifting. Monophonic pitch shifting (especially in the sub-semitone range that Auto-Tune does) has been done with high quality since the 1970's.
I thought from the title that it goes into the mathematics. Unfortunately all the article says w.r.t math is a hand-wavy explanation of autocorrelation. But it was an interesting story about the life of Auto-Tune's creator.
I've worked with Hildebrand myself - he's one smart cookie, for sure.
edit/tidbit: he told me that the interview process for hiring new developers goes like this: all the questions are straight out of K&R's C Programming Language, you have to get all of them correct, and so far only one programmer has :P
I have an eidetic memory and have read that book multiple times, so there’s a fair chance I’d pass. That said, if I was given that interview as you described, I’d get up and walk out. Interviews like that prove absolutely nothing useful to evaluating a candidate and thus are a waste of time.
Because the eidetic memory only lasts for a few minutes. The commentor might have meant to use the phrase “photographic memory”, but that has thus far been shown to be myth. But, really, the post was about “I’m smart, and I’d just march right out of that interview”, ignoring that it was just a cute anecdote, so I guess it’s irrelevant. Nice catch, though. :-)
>"Seismic data processing involves the manipulation of acoustic data in relation to a linear time varying, unknown system (the Earth model) for the purpose of determining and clarifying the influences involved to enhance geologic interpretation. Coincident (similar) technologies include correlation (statics determination), linear predictive coding (deconvolution), synthesis (forward modeling), formant analysis (spectral enhancement), and processing integrity to minimize artifacts. All of these technologies are shared amongst music and geophysical applications."
That is dramatic hand-waving, but it does help convey to non-programmers how dramatic an improvement the right algorithm can implement.
It's true what the article says that pitch tracking was considered a difficult "holy grail" in 1995. I attended a talk about pitch tracking at Interval in 1996 by somebody whose name I don't remember any more. The speaker made the point that pitch is a perceptual -- not a mathematical -- concept, and it was hard but possible to do it in real time on a typical PC at the time (i.e. 90 MHZ IBM ThinkPad 760C). But he had done it, and everyone seemed impressed by his demo! ;)
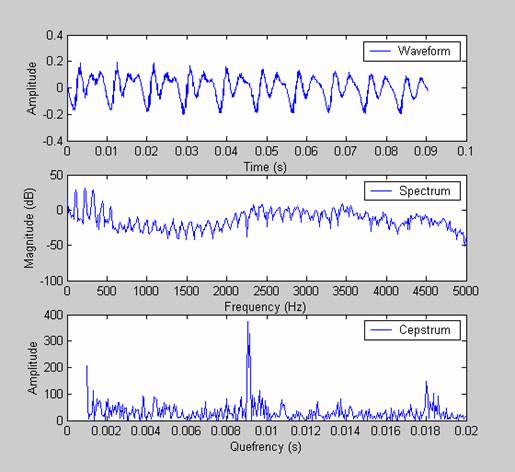
The article mentioned formant analysis. Maybe that's related to cepstral analysis, which is another way of tracking the pitch and formants of voice, and has its own cool nomenclature of secret code words. "Cepstral liftering" is basically two FFT's followed by an inverse FFT.
If you take the complex FFT of a voice signal, the formants show up as two or three large "hills" in the spectrum, but the pitch manifests as higher frequency repeating furrows in the hills. (Which you want to filter out so you can analyze just the formants, or synthesize a different pitch into them (i.e. auto-tune), so you need to know the frequency of the change in the spectrum magnitude over time: another FFT!)
So you take a second FFT of the log of the first FFT, to get a "reverse spectrum" or "cepstrum" in the "quefrency" domain. The fundamental pitch shows up as one big spike in the cepstrum (with smaller spikes for its harmonics). Just "lifter" out the pitch spikes, then perform an inverse FFT to get back to the smooth low frequency formant hills with the high frequency pitch furrows removed.
I'm sure there's a lot of "special sauce" in getting the math tweaked and tuned right so it actually sounds good and runs fast.
The patent seems to be about autocorrelation, which is something different than cepstral analysis, but maybe they could be used together to get even better results.
I don't know but would love to learn what the trade-offs and limitations the two techniques have.
>The name "cepstrum" was derived by reversing the first four letters of "spectrum". Operations on cepstra are labelled quefrency analysis (aka quefrency alanysis), liftering, or cepstral analysis.
"The original application was to the detection of echoes in seismic signals, where it was shown to
be greatly superior to the autocorrelation function, because it was insensitive to the colour of the signal."
Are there some examples of Auto-Tune used with more subtle settings? Famous Cher song used it at setting 0, robotic sounding one, but there are 10 more to go, and they are increasingly more subtle.
Also related to this, at least I think, is the issue of turning recording into midi or sheet music. Now that would be a killer app... There is some good software out there, such as Melodyne, but it requires a lot of manual work and tweaking.
It's been years since I've done music recording as a hobby so someone correct me if I'm wrong -- you can be guaranteed that almost all popular music is pitch corrected in some way. There's Autotune and then there are other ways of pitch correction as well -- Melodyne allows you to manually adjust pitch at a microscopic level. I was able to use Melodyne to perform manual pitch correction that sounded far more "natural" and non-exact than auto-tune.
Of course a lot of folks cannot tell the difference, but to me it's night and day. I couldn't stand Glee for instance because of how auto-tuned the voices were.
> I couldn't stand Glee for instance because of how auto-tuned the voices were.
This was pretty obnoxious when I noticed it; I don't mind if they use auto-tune for a one-off musical episode of a show, but for a show where every episode is a musical to use it (and not very subtly) was very off putting.
I have a little experience with the recording process, having been involved in the production of a contemporary a cappella album, and I think most people wouldn't believe how much stuff is auto-tuned. To my ear, if you listen to something like the Pitch Perfect soundtrack, a lot of it sounds quite obviously pitch corrected, but I will play it to musical friends and they are often surprised when I tell them there's some serious auto-tune going on.
Outside of the a cappella domain, I believe it's pretty prominent in most pop music, but my understanding is that the technology's gotten to the point where 95% of the time you can't tell apart machine correction from good tuning of the vocalist.
True. Inserting anything that doesn't exist in the first place, like a plane, train, animal, or monster is incredibly jarring for even the most casual movie watcher. It's a bit sad that we can't create convincing things out of thin air using CGI in 2017.
Just about all childrens' shows with singing use it, I think. Some on harsher, obnoxious settings (Daniel Tiger's Neighborhood), some still very noticeable but toned down a bit (MLP). Someone could probably put together a spectrum of auto-tune settings samples from such shows.
I hate it because it's throwing off kids' sense of what a natural human singing voice sounds like. It's photoshop for the voice and is similarly damaging to one's image of self and of others.
Steven Universe isn't strictly a kids' show, but it has some noticeable imperfections in many songs which I think adds a sense of honesty without hurting the performances. I hate the perfection in Daniel Tiger songs, they will contribute to a generation of kids that cannot stand the sound of their own voices.
Now, while it's possible that he simply became a better singer between 2007 and 2015, subtler auto-tuning of the type conventionally used in pop production generally just makes the voice sound cleaner, thicker, more polished. Note that his style has also changed to favor staccato phrasing so as to limit stairstepping artifacts.
> makes the voice sound cleaner, thicker, more polished
I think here you may be confusing Auto-tune with "modern" voice processing, which while happened together are quite different. Modern pop singers are overdubbed ridiculously with added distorsion, resulting in a "massive" (and slightly "robotic") lead voice.
I'll try to walk you through what I'm actually hearing that makes me think there's Auto-Tune there:
- 2:50: Subtle, but as the first "oh" starts, it sounds like it quickly jumps from a slightly lower note to the correct one.
- 2:58: The word "part" has a classic Auto-Tune sound. The real recording probably went slightly off pitch as the note was held and Auto-Tune has made it perfect and a little robotic.
- 3:07: "Where" has a similar sort of robotic pitch slide sound as it starts as the "oh" did earlier.
- 3:13: "Discover" has a sort of a glitch in the middle as Auto-Tune tries to track across the 'k' sound in the middle of the word.
As someone else already said, songs in TV show Glee used it all the time in a fairly obvious (but still subtle compared to intentionally sounding Auto-Tuned) way.
The lead singer's voice just sounds so thin, and unnaturally on-key (no vibrato).
I think you'd be hard-pressed to find verifiable examples because those higher settings are probably mostly used to cover up poor singing, and so nobody involved is going to volunteer that information.
I didn’t listen to much of this, but the two seconds I heard “I guess it’s all the..” there’s definitely clear artifacting from either auto-tune or compression on the word “all”. And I’m listening on an iPhone.
Yeah, I've used it on "live" recordings with saxophone* to cut out the number of overdubs necessary. On subtle settings, it's impossible to hear the effect of it.
*Sax was the only non-fretted/pitched instrument in that recording.
Melodyne is way more advanced : you can isolate individual notes and choose the pitch yourself, whereas with auto-tune you choose a scale and it automatically correct to the nearest note. See this link posted in another comment : https://www.youtube.com/watch?v=9FScFKuXXM0
The interface is different with some different parameters. I don't know how the actual mathematics involved compares, but the sounds you'll get out of it are a little different. It's still a good option to listen to to hear what pitch correction on vocals might sound like in general.
Lol, obviously didn’t read the article which had an entire section dedicated to how auto-tune has such a successful brand that it’s used in speech the same as Kleenex, Google, etc
I figured whether it was meant in a genericized way or not, it's still useful to point out the specific product used to someone who's wanting to hear what it sounds like, since they each have their own sound to some extent.
The ubiquity of auto-tune is particularly interesting because most people don't seem to have a lot of pitch sensitivity. Tons of very famous recordings are slightly out of tune and no one seems to complain, ever.
I'd imagine its popularity is more due to convenience rather than demand.
The one genre I can think of where perfect tuning is essential is barbershop music. The defining feature of the genre is chords sung with just intonation and no vibrato, which makes it easy to hear if any of the singers are out of tune. See:
A lot of barbershop albums, probably most recent ones, are pretty heavily pitch-corrected. It doesn’t bother me that much, but I almost always prefer live barbershop recordings.
Depends what you mean by "out of tune". How good a chord sounds is determined by the ratio of frequencies, not if all the notes fit 'perfectly' in some scale. In fact you can't even create a scale where all chords are perfectly in tune.
agreed, but even in classical music it doesn't really bother me that much sometimes, some of my very favorite string players have occasional intonation issues (who doesn't?). And think of all the jazz records with an out of tune piano!
yea, sometimes i think the lack of perfection helps you focus on the bigger ideas. like how making 2d plots with the xkcd style kind of tells your brain to ignore little noise in the line. same with tuning and tempo and whatnot- not every not is perfect, so your ear ignores the little imperfections. of course, if there is too much imperfection, signal to noise ratio gets out of whack. but i think this is part of the reason lots of music has drones, melocially, or texturally (think indian classica, jazz cymbal or brushes, etc) ...it kind of thresholds alot of non-musical noise.
I had always assumed that Auto-Tune had evolved from or was an advanced form of Vocoder (likely from the similar "robot" effect extreme applications of Auto-tune gives).
I've been working on a relatively simple real time music/audio processing project on an Arduino (identifying tempo and using it to create interesting lighting effects for a Halloween costume) and it's an interesting challenge. Extracting any kind of useful information about the underlying musical structure from polyphonic audio is an incredibly hard problem. Add to that limited hardware and the kind of sampling rate you need to capture music (upwards of 40kHz if you want to capture everything you can hear) and you have to get creative.
It's definitely a challenge with something like a microcontroller. My coding skills are borderline nonexistent (but then again, that's part of why I'm experimenting with Arduino in the first place) but I've messed around with using some FFT code published by others to get audio to affect some LED strips. So far the results have been mixed.
What he (Andy, or was it someone else at Antares? I forget..) told me is that raspy heavy metal vocals are the one type of vocal that doesn't really work with Auto-Tune that nonetheless constantly get requested to get to work
wondering if anyone has listened to Guns N Roses live this past year or so. Axl Rose's voice sounds amazing, considering his age, style of singing, and his well documented hard living. Having listened live at coachella and watched online,
im wondering if its possible they are doing it live in real time now.
{kind=link}
I think this is the article's way of dramatizing the standard way of calculating the autocorrelation using the convolution theorem: https://en.wikipedia.org/wiki/Autocorrelation#Efficient_comp...