There is a public distributed effort happening for Go right now: http://zero.sjeng.org/. They've been doing a fantastic job, and just recently fixed a big training bug that has resulted in a large strength increase.
I ported over from GCP's Go implementation to chess: https://github.com/glinscott/leela-chess. The distributed part isn't ready to go yet, we are still working the bugs out using supervised training, but will be launching soon!
We are using data from both human grandmaster games and self-play games of a recent Stockfish version. Both have resulted in networks that play reasonable openings, but we had some issues with the value head not understanding good positions. We think we have a line on why this is happening (too few weights in the final stage of the network), but this is exactly the purpose of the supervised learning debugging phase :).
This is really cool! The chart on that page makes it look like Leela Zero is already much much better than AlphaZero (~7400 Elo vs ~5200 Elo). I suspect I'm misinterpreting something though, could you clarify?
Leela Zero's ELO graph assumes that 0 ELO is completely random play, as a simple reference point.
On the other hand Alphago uses the more common ELO scale where 0 is roughly equivalent to a beginner who knows the rules, so you can't directly compare the two.
I've been having fun following along with Leela Zero, it's a great way to understand how a project like this goes at significant scale. Good luck with Leela Chess, I'm excited for it!
Sequential probability ratio test, it is essentially a test that distinguishes between two hypotheses with high probability.
In the case of Leela Zero the idea is to train new networks continuously and have them fight against the current best network, which is replaced only when a new network is statistically stronger, according to SPRT.
In 1989, Victor Allis "solved" the game of Connect 4, proving (apparently) that the first player can always force a win, even if both sides play perfectly.
In 1996, Giuliano Bertoletti implemented Victor Allis's strategy in a program named Velena:
It's written in C. If someone can get it to compile on a modern system, it would be interesting to see how well the AlphaZero approach fares against a supposedly perfect AI.
To benchmark A0 further, you can take whatever NN you're training and instead train it against the 'ground truth' of Velena's moves when going first (the NN predicts for each possible move if Velena would take it or not, 0/1 labels). Then one can know how close does the A0 NN trained via expert iteration approaches the Velena-supervised NN and how much compute is spent on the need to train from scratch?
Can someone share some intuition of the tradeoffs between monte-carlo tree search compared to vanilla policy gradient reinforcement learning?
MCTS has gotten really popular as of AlphaZero, but it's not clear to me how this compares to more simple reinforcement learning techniques that just have a softmax output of the possible moves the agent can make. My intuition is that MCTS is better for planning, but takes longer to train/evaluate. Is that true? Is there some games one will work better than the other?
In vanilla policy gradient, one plays the game to the end and then bumps the probability of all actions taken by the agent up (if AlphaGo won) or down (if it lost). This is very slow because there ~150 moves in an expert game, and we do not know which moves caused decisive victory or loss - i.e. the problem of "long term credit assignment". Also, it is actually preferable to compute the policy gradient with respect to the advantage of every action, so we encourage actions that were better than average and punish actions that were worse than average - otherwise the policy gradient estimator has high variance.
I think about MCTS in the following way: suppose you have a perfect "simulator" for some reinforcement learning task you are trying to accomplish (i.e. real-world robot grasping for a cup). Then instead of trying to grasp the cup over and over again, you can just try/"plan" in simulation until you arrive at a motion plan that picks up the cup.
MCTS is exactly a "planning" module, and it works so well in Go because the simulator fidelity is perfect. AlphaGo can't model adversary behavior perfectly, but MCTS and the policy network complement each other because the policy reduces the search space of MCTS. As long as the best adversary is not far away from the space that MCTS + policy is able to consider, AlphaGo can match or beat the adversary. Then, we train the value network to amortize the computation of the MTCS operator (via Bellman equality). Finally, self-play is an elegant solution for keeping adversary + policy close to each other.
Thanks for the response! I'm familiar with how AlphaZero works, just primarily curious about how performance/speed compare in situations with perfect information and where it is possible to perfectly simulate (pong/go/chess/etc).
I did not realize that MCTS helps with the credit assignment problem, that's really interesting!
Thank you very much for the clear explanation for MCTS Vs. vanilla policy gradient
>In vanilla policy gradient, one plays the game to the end and then bumps the probability of all actions taken by the agent up (if AlphaGo won) or down (if it lost). This is very slow because there ~150 moves in an expert game, and we do not know which moves caused decisive victory or loss - i.e. the problem of "long term credit assignment".
>I think about MCTS in the following way: suppose you have a perfect "simulator" for some reinforcement learning task you are trying to accomplish (i.e. real-world robot grasping for a cup). Then instead of trying to grasp the cup over and over again, you can just try/"plan" in simulation until you arrive at a motion plan that picks up the cup.
The MCTS variant used by AZ offers a big advantage in the exploration/exploitation tradeoff, with a better exploration profile during training and better exploitation during competitive play.
The training phase emphasizes exploration using a modified upper confidence bound for tree search criteria to limit the expansion of the search tree. With a uniform prior over the action space (like standard MCTS), you will explore a large number of unlikely actions. The prior provided by the NN allows them to bootstrap the value of leaf nodes _and_ efficiently sample the actions at each state. AZ has eliminated the simulation phase of MCTS entirely.
AZ uses different criteria for move selection during training and during competitive play. The competitive selection criteria basically replaces the UCBT criteria with standard argmax over the actions (like a normal RL policy selection). We know that tree pruning can be very effective during search _if_ you can order the nodes in a beneficial way. AZ MCTS uses the output of the NN as the prior instead of a uniform prior, which is like a "virtual" pruning (because moves with low probability in the prior are unlikely to be explored). This tends to more quickly focus the search on strong lines of play, so the algorithm produces strong choices with less search (AZ uses about an order of magnitude fewer expansions than other state-of-the-art MCTS engines).
MCTS has always been popular and probably the best online/out-of-the-box MDP technique. But fundamentally its different than RL methods. In MCTS you assume you have a perfect simulation of the MDP which is rarely true outside of games. MCTS also doesnt really have a learning phase.
> My intuition is that MCTS is better for planning, but takes longer to train/evaluate.
There is no training phase in MCTS, rollouts can take a while, its important to have a fast simulator and rollout policy (like random/UCT).
> Is there some games one will work better than the other?
Sorry, I was referring specifically to AlphaZero's approach in which there is training for the expert policies that guide the MCTS. And yes I'm assuming there is perfect information and it can be simulated. Thanks for the response!
It has been a while since I read the paper, but I believe they have some results where they ran AlphaZero without MCTS, using only the policy network. My recollection is that is still performed pretty well, but it was clearly outperformed by MCTS.
Favorite line from it: "AI blew the gates of the Go palace open. And we realized there was no one inside."
Another interesting thought was when one of the developers gets asked why bother to clone AlphaGo when AlphaGo already exists, he says something like "Was it pointless for China to develop the atomic bomb even though the USA already had?"
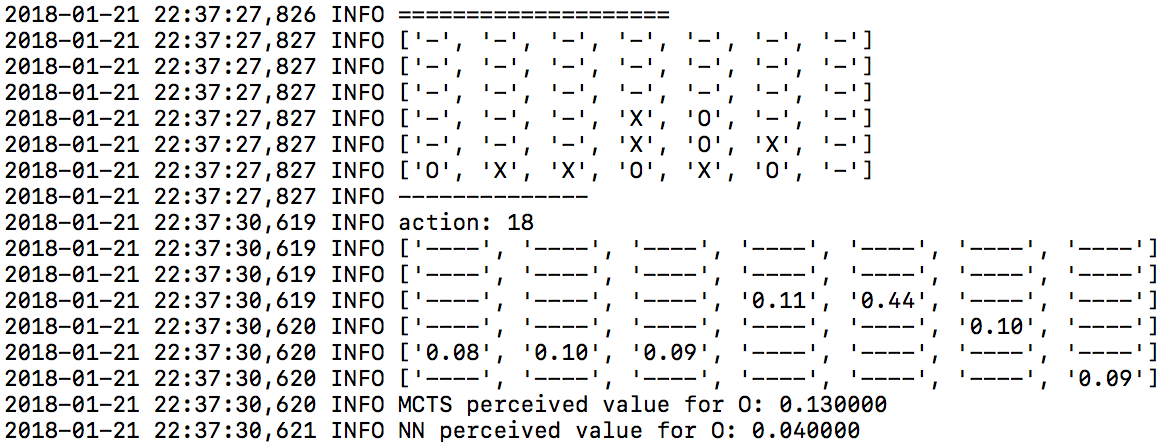
Shameless self plug. I spent a Saturday morning doing a similar (no monte-carlo, no AI library) thing recently with tic-tac-toe. I based this mostly on intuition, would love any feedback.
I've only skimmed it a little bit so far, I'm just wondering, if both players use the optimal strategy, shouldn't the game always result in a draw?
Which is why I was a bit confused by the target '80% Win/Tie rate going second', but I could well be missing something.
Edit: I'm an idiot, I see that the opponent takes random moves now. Seems a fun project :), a while ago I built a very simple rule-based tic-tac-toe thing in lisp, but the rules were all hardcoded alas.
So I’m not the person who posted the code, but I don’t think I really understand what you mean but I want to learn from it. Can you explain what it would mean in practical/layman terms to resume his work better?
> Not quite as complex as Go, but there are still 4,531,985,219,092 game positions in total, so not trivial for a laptop to learn how to play well with zero human input.
That's a small enough state space that it is indeed trivial to brute force it on a laptop.
Putting aside that though, it would be interesting to compare vs a standard alpha-beta pruning minimax algorithm running at various depth levels.
Is there magic incantation I have to say to get this to compile? Jupyter says I'm missing things when I try to run it (despite installing the things with pip)
Too vague. Do you predict that AlphaZero will not be able to beat humans in a game like Go but where there's 1 in 100 chance for a stone to land in unintended place?
{kind=link}
I ported over from GCP's Go implementation to chess: https://github.com/glinscott/leela-chess. The distributed part isn't ready to go yet, we are still working the bugs out using supervised training, but will be launching soon!