The formatting of this article itself is something worth studying. It's brilliantly seductive to read and read all of it. The pictures/slides by each paragraph were like rewards, continually luring me to the next paragraph. For the first time in a long time. I read every single word. Not skimmed.
Although I disagree with the idea of regulating how long behavioral data is saved. Not all behavioral data is sensitive. Rather we should consider fully disclosing to users either how long their data will be saved or what data has been collected on them or both. Any other regulations may be too burdensome to the startup.
=== Examples ===
His suggestion that all behavioral data be deleted after a certain period of time means every little piece of data collected must also have a timestamp. Inflating databases and costing money.
A program must be written that seeks out timestamped data ready to expire and delete it.
If the deleted data is connected with other pieces of data or reports elsewhere we're going to run into complex problems.
These obligations must be handed down from company to company during acquisitions. A company selling data about to expire will get acquired for a lot less than a company with fresh data. This may in turn cause a series of unforseen consequences in the acquisition market.
=== Solution ===
Rather than controlling and manipulating what can and cannot be done, it may be best to just create transparent policies and let the free market converse its way towards a compromise.
Maybe not, but I am surprised on a regular basis at inventive new uses for data that I had never before imagined. At this point, I think a safer default is, "all behavioral data is sensitive", until we better understand how all of this stuff works.
> Inflating databases and costing money.
Everything costs money. It is meaningless to point out that something costs money without attaching a number to it. Databases would be inflated by four or 8 bytes per datum; at 500 million rows, you'd add between 8 and 16 GB to a database that is likely very much larger already. I really don't see this being an insurmountable engineering challenge.
> These obligations must be handed down from company to company during acquisitions. A company selling data about to expire will get acquired for a lot less than a company with fresh data. This may in turn cause a series of unforseen consequences in the acquisition market.
This is a feature, not a bug.
> Rather than controlling and manipulating what can and cannot be done, it may be best to just create transparent policies and let the free market converse its way towards a compromise.
One of the central points of the lecture was that there is insufficient competition in some very important parts of the internet right now. Those companies could easily say, "Our policy is that we keep everything forever and there's nothing you can do about it", and it would not affect their business at all because they have no competitors.
Regulations exist in the real world for a good reason, and we're rapidly approaching a point where regulation is exactly the appropriate solution for some of these problems.
>let the free market converse its way towards a compromise.
There's no "free market" that's an ideology (a made-up idea of how the world is that obscures one's thinking).
With government: I have more money than you, and I have friends in Washington. I'll use it to push things my way.
(And lest somebody suggest: "sure, the problem is government", here's the government less version:)
Without government: I have more money and/or power than you, and I have you beat to a pulp, and also spend it to make people go along with my propositions. I'll use it to push things my way.
Usually is a mix of 1 and 2. E.g most Latin American countries, for example, there's not much of a "free market" with regards to their exports/materials because stronger countries force them (with military might, diplomatic pressure, juntas, putting friendly lackeys in power, briding, etc) to go with their way. A powerful country can spend tens of millions of dollars just to promote a favorable candidate in power in a smaller countries (easily recouperated in a day's worth of profits from resource and trade agreements).
And of course with things as a patent system, intellectual property, etc, there's no free market also. The IP owner sets the terms, and you cannot offer the same thing for a reduced price even if you can.
> There's no "free market" that's an ideology (a made-up idea of how the world is that obscures one's thinking).
Everything is a made up idea that obscures one's thinking. I think I have to drive on roads, but really nothing is stopping me. I could get through traffic faster if I just started driving on the shoulder, but the problem is if everyone did that it would be chaos, and would be worse overall. Systems have the potential to create a net good.
Well, the "have to drive on the road" is a "law" or an imperative not an ideology. People know it's a made up convention so that we don't hit each other or depestrians.
People talking about free market, on the other hand, think of it as a real, concrete thing, and even further, that it has this and that properties. Thinking thusly about a made-up thing can have dire consequences -- like when hallucinating on drugs and jumping from a building to avoid a huge snake.
I'm going to have to disagree--how often do you have a "created_at" field in your data?
Moreover, how useful is it to see when data was collected? You pretty much need that to be able to model user behavior over time.
If the deleted data breaks a report, that's in line with what the user wanted--failing that, you should've used a proper design pattern to transparently fill in the gaps.
Let's not pretend that this would actually be anything other than a minor annoyance.
EDIT:
A program must be written that seeks out timestamped data ready to expire and delete it."
Here, let me help, after one second on Stack Overflow:
DELETE FROM Table WHERE DATEADD(year, 2, CreateDate) < getdate()
There's your program. Anybody want to show how to do this in Cassandra or Mongo? Might as well put that NoSQL map/reduce to work...
It doesn't make sense that a company would expire data, it's not illegal, and users are not the customers to companies like Facebook, and Google. Users are the product to advertising.
A more concrete solution would be to own our own data for these kinds of services, and pay for the active development & hosting. I'm all for this, and hope to see business like this in the future, I would definitely pay for Facebook if it were possible.
Some issues I could see with allowing the free market to yield, is allowing interoperability with existing services. Is it illegal to plug Diaspora into Facebook and redirect friends to my service? I'm sure it's against their ToS, and I bet Facebook will do everything in it's power to protect it's product.
Also, credit card fees make it difficult to implement micro transactions. If I charge someone $1, 32.9% will go to fees [1]. I like fiat currencies, but the government should really step in and clean up the infrastructure. Credit card companies are centralized services for our transactions, held in power by the government. Paying with cash is amazingly decentralized, and crypto currencies accomplish the same effect on the internet. If our government designed a better currency for the internet, it would give more power to the free market.
> His suggestion that all behavioral data be deleted after a certain period of time means every little piece of data collected must also have a timestamp. Inflating databases and costing money.
I'm not convinced that startups are such an inherent social good that they need to be insulated from the costs of responsible behavior.
> These obligations must be handed down from company to company during acquisitions. A company selling data about to expire will get acquired for a lot less than a company with fresh data. This may in turn cause a series of unforseen consequences in the acquisition market.
Working as intended. Forcing companies to be responsible will cut down on rash, irresponsible acquisitions.
But he also suggests "Let users opt-in if a site wants to make exceptions to these rules". I would think every website would just add a click-through opt-in, undercutting the regulations. How would one prevent this from happening?
The formatting of this article itself is something worth studying. It's brilliantly seductive to read and read all of it.
I couldn't agree more. This had been exactly my thought as well, as soon as I finished reading. For some reason the presence of those photos on the side made me read absolutely every single word. And personally, I haven't paid attention to every single photo, but their mere presence persuaded me to read the paragraphs in their entirety.
It's very intriguing how the first part of your comment captured my thoughts so accurately. (:
This is a great quote, and very timely with the recent metafilter kerfuffle:
"If you don't run your own ad network, advertising is a scary business. You bring your user data to the altar and sacrifice it to AdSense. If the AdSense gods are pleased, they rain earnings down upon you."
"But if the AdSense gods are angry, there is wailing, and gnashing of teeth. You rend your garments and ask forgiveness, but you can never be sure what you did wrong. Maybe you pray to Matt Cutts, the intercessionary saint at Google, who has been known to descend from the clouds and speak with a human voice."
I have come to believe that businesses should not be legally allowed to store any consumer data unless it's obvious to the consumer that it's absolutely required for the primary function of the service, and they should only be allowed to store data for that one function, with an exception if the consumer explicitly and voluntarily opts-in for each additional function.
Large internet companies have been collecting swathes of data with the claim that they are secretly using it to improve people's lives. But it seems to me that A/B testing has failed to improve anyone's life.
Example:
I use search engines to search for something I'm looking for.
I do not benefit from being shown 'targeted' ads, nor from the search engine identifying the most populist answers which it uses to spoon-feed me later rather than serve what I asked for, nor from the search engine identifying which particular arrangement of pixels will leave me personally more addicted.
Businesses are welcome to use my data in ways which are in my interest, but they should not get to decide which of these uses are in my interest.
1. The issue of what is "in your interest" is not so black and white. For instance, one of the reasons Google is still so popular is because it more consistently returns the results we want. On many DDG discussions (or Bing-related discussions when it was still being discussed), this has been raised as a deal-breaking issue for many people. Google's results are often more relevant and useful. This is in part because of Google's vast store of consumer data. Now, you may argue that their results are better for other reasons, but the fact is that using their consumer data is an integral part of their ranking algorithm, and people like their ranking algorithm.
2. On a more cynical note, it seems that governments and corporations are aligned in their interest to collect as much data about citizens as possible. I doubt that the U.S. government will mandate a reduction in storage of consumer data, when they themselves benefit regularly from that data thanks to widespread use of NSLs and other legal and extralegal demands.
1.
Sure. My point is that I should have the right to choose what's in my interest, rather than have a company tell me what's in my interest. At a minimum, companies should explicitly say exactly what they are doing with my data. That's part of our agreement, after all. I use DDG for this reason. Actually I'm not super-happy with DDG in this respect: I believe there is some shady blurring of their promotional message vs the small print. But I would rather support DDG than Google, for now.
I don't think DDG needs to or should be catering for the people who find a lack of super-personalised results deal-breaking:
a) the world certainly doesn't need DDG to ape Google. There needs to be more competition in this space, and DDG's position distinguishes it. I hope and believe there is a market for a variety of search engines (as there are around the world).
b) in blind-testing, I'm not aware there is any evidence that Google does better.
2.
I hold out hope that the EU data protection principles will one day be properly upheld within the EU. I have no such hope for the US government.
>There was an ad for the new Pixies album. This was the one ad that was well targeted; I love the Pixies. I got the torrent right away.
I laughed very hard on this!
In all, an excellent article. I disagree with blind faith in technology to solve all our problems and not create new ones
People often forget that technology is tools (and not always neutral tools, as is another naive belief: some inventions have larger inherent "harm potential"), and that policy matters as much, or even more, as does the kind of cultural landscape we guide our use of the tools.
The thesis the talk pivots around is this one, in my reading:
"Investor storytime only works if you can argue that advertising in the future is going to be effective and lucrative in ways it just isn't today. If the investors stop believing this, the money will dry up."
It's worth noting that web advertising is still small potatoes compared to more traditional channels- and the traditional channels make it astonishingly difficult to measure effectiveness. There's an awful lot of money in selling Coca-Cola, and Pinboard & Facebook haven't scratched the surface.
It is a minority of the total, but it is getting up to about 20-25% of the total. Some of that market, like ads on public transportation, billboards, flyers, kiosks, etc. is not accessible to Web media, so the share of the accessible market is a bit higher. It's not as if the ceiling remains out of sight.
Your comment about traditional ad measures of effectiveness being dodgy probably means pricing will decline when effectiveness can be accurately measured, so that means Internet ads have a still higher share of the theoretical maximum.
I've been wondering - is there a point when people lose faith that they're getting ROI by buying adwords?
Isn't it possible that the culture may just stop giving money to Google at some point?
And then no more aqui-hires, so no more inflated valuations, and then most of us go back to whatever we were doing before we were working at startups, right?
We read this, nod wisely, and go back to working on our centralized services for VC's who hope to own part of a monopoly. "One day, this will change" we think to ourselves.
Still reading the talk, but as an aside wanted to point out that the way the transcript is formatted with the words alongside the slides is probably the best way I've seen a talk presented in text form on the internet.
There's a rather hilarious portion (in an otherwise soul-crushing deck): the author is trying to figure out what this massive dragnet and mining of their information has actually gotten, and so they look at all of the ads they get served. This bring forth this gem:
"There was an ad for the new Pixies album. This was the one ad that was well targeted; I love the Pixies. I got the torrent right away. "
The thing I wondered was whether that was deliberate or not. Charles Duhigg talks about this in his book on habits. Target has the data to identify expecting mothers. Rather than bombarding strictly baby related photos, they careful include seemingly other unrelevant ads so it doesnt come off as intrusive.
Although I will say that in my own ad experience, the ads have generally been more related to my interests than this author describes. .
Hearing the anecdote, it’s easy to assume that Target’s algorithms are infallible – that everybody receiving coupons for onesies and wet wipes is pregnant. This is vanishingly unlikely. Indeed, it could be that pregnant women receive such offers merely because everybody on Target’s mailing list receives such offers. We should not buy the idea that Target employs mind-readers before considering how many misses attend each hit.
In Charles Duhigg’s account, Target mixes in random offers, such as coupons for wine glasses, because pregnant customers would feel spooked if they realised how intimately the company’s computers understood them.
Fung has another explanation: Target mixes up its offers not because it would be weird to send an all-baby coupon-book to a woman who was pregnant but because the company knows that many of those coupon books will be sent to women who aren’t pregnant after all.
None of this suggests that such data analysis is worthless: it may be highly profitable. Even a modest increase in the accuracy of targeted special offers would be a prize worth winning. But profitability should not be conflated with omniscience.
> If you have Web History enabled, this data may also be stored in your Google Account until you delete the record of your search.
> When you create a Google Account, Google Web History is automatically turned on.[0]
So for everyone who has a Google account, and who hasn't taken specific steps to disable "web history" (read: 99.9% of users) they're storing that data indefinitely.
The site you linked links to https://history.google.com/history/lookup , where you can see all of the searches Google associates to your account (if you have web history enabled).
Fantastic as always. Every time I read one of Maciej's talks or essays I get a little closer to throwing in the towel and pursuing a more meaningful existence. It's going to happen one day and I can't wait to read the post that forces it.
Just a note about the whole "buying $500 triggered the police to be alerted because of money laundering" notion...
The actual quote from the mashable article was:
>When her husband tried to buy $500 worth of Amazon gift cards with cash in order to get a stroller, a notice at the Rite Aid counter said the company had a legal obligation to report excessive transactions to the authorities.
So in reality, they made a big stink about the fact that they noticed that Rite Aid practices safe KYC laws and would report suspicious money-laundering activities to the government. As they must. Lest they expose themselves to money laundering charges as well.
That isn't to say that the clerk who sold them the $500 gift cards immediately picked up the phone as they were walking out the door and called the cops... that just means that if they notice you regularly buying $10,000+ worth of gift cards with cash only AND they just don't like the look of you in general, that they may pick up the phone and call the police.
Ditto the kudos on the formatting. This piece really resonated with me. As for solutions, I have none. Hopefully someone smarter and more resourceful than me will be inspired by this talk.
This was excellent. It described some of the reluctance I've had towards social networks since 2000 at least.
It's also a little bit funny that it was written by the guy behind pinboard.in, a nice social bookmarking service (where many people went when del.icio.us died). But that makes me trust the service more, not less.
Pinboard does describe itself as "antisocial bookmarking" (and "Social Bookmarking for Introverts"). Delicious seemed to me to be about making bookmarking social. Pinboard seems to be about bookmarking with some social options.
Much of what the author suggests in terms of regulation already exists in most European countries, and most of it pre-dates the commercial rise of the internet.
Sure, much of the wording and enforcement is lagging behind today's reality, but the principles are clear: data about me is my data. Companies are not free to collect, collate and keep anything that they can get their hands on.
Facebook, Google et al are breaking the laws of countries they operate in on a massive scale. The backlash is being tempered by massive lobbying from those companies and the US government.
Not to mention the media propaganda (media are part of the advertising mafia), as seen in the recent wave of scaremongering bullshit about the "right to be forgotten" verdict.
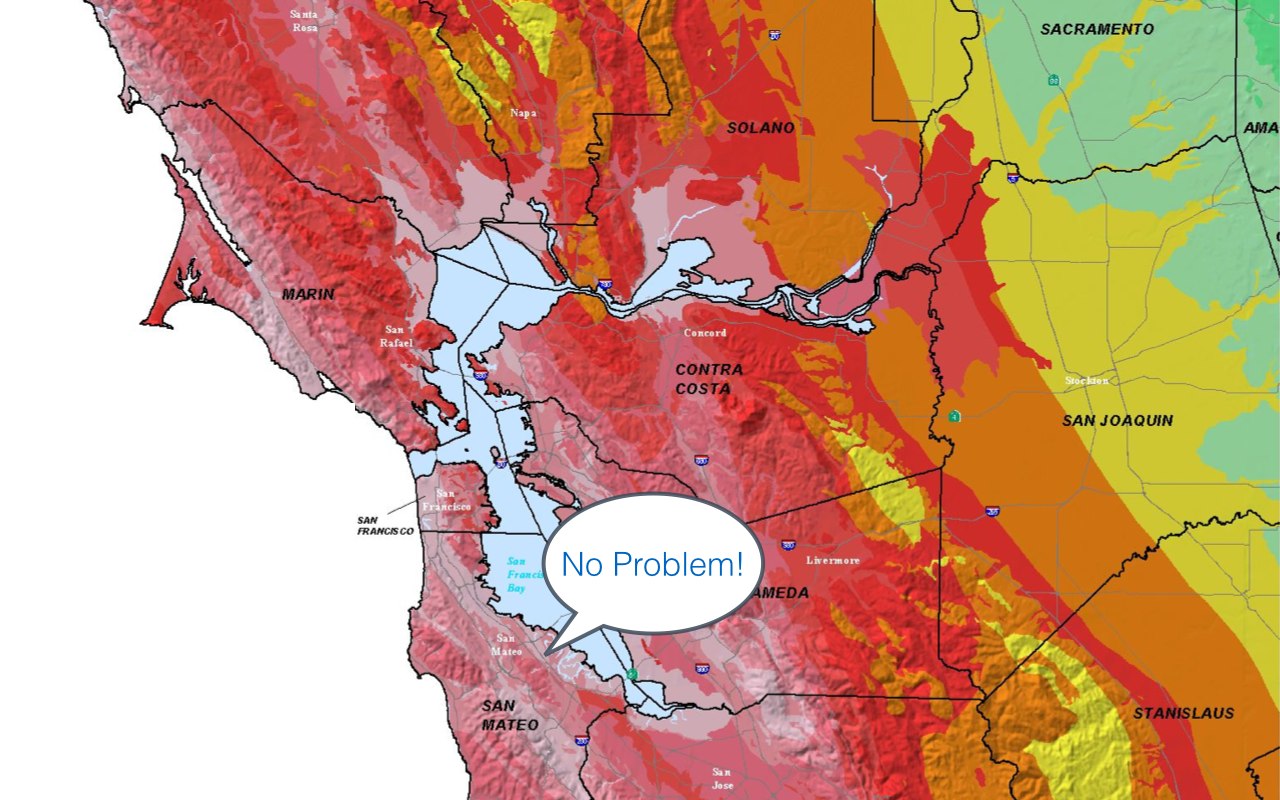
This festive map shows seismic hazard in Northern California, where pretty much all the large Internet companies are based, along with a zillion startups. The ones that aren't here have their headquarters in an even deadlier zone up in Cascadia. (...)
So even if you don't agree with my politics, maybe you'll agree with my geology. Let's not build a vast, distributed global network only to put everything in one place!
That slide[1] hits close to home. I'm painfully aware of how hard (and almost pointless/powerless) it is to reason about long-term geological risks, esp compared to less catastrophic and more (short-term) predictable hazards like hurricanes, tornadoes or blizzards; but from time to time I idly question the wisdom, from a civilizational point of view, of having so many concentrated, incredibly talented people living directly atop one of the most dangerous fault regions on earth[2].
But again, it's pointless to think about it as an individual, so better get back to work and keep living day by day, I guess. Wovon man nicht sprechen kann...
Maciej is over-estimating the risk potential here. Or, to be more precise---the companies that have headquarters in the Valley are aware of the risk potential and have contingency plans to mitigate it.
Not that I'm against seeing some great software companies grow out of other geographic locations; I'm merely noting that it's not necessary to do so to avoid the threat of earthquake-related disruption. Threat known and accounted for.
Perhaps. A awful lot of wealthy and reputable companies thought they were solidly prepared against cracking attempts, too. It's harder to take their word for it now than it was five years ago.
One issue is that big data is just too big for the small minds that are tasked with gaining insights from it. It is a really weird hysteria that I can't explain. Even network engineers are starting to collect every packet and archive it in some kind of distributed data store like HDFS. What insights are they going to gain from it exactly? If the goal is security then work on better network infrastructure and tools, e.g. libressl. Collecting all that data is not going to get you any closer to making better/smarter networks or allow you to fight DDoS attacks any better because the underlying network infrastructure is what makes it possible in the first place.
Very well written, but a little unconvincing: he does a great job showing the ads he's bombarded with on Youtube are completely irrelevant to his personal situation.
Of course, it could be that advertisers are inept. That's what he implies.
But it could be, they don't have access to all the data he/we fear they do. Maybe this data doesn't even exist in the first place, or is downright unusable.
This is going to be a fairly controversial opinion, and I fully expect this text to end up about one shade off white approximately five minutes after posting (at least if my last few attempts mean anything, hence the following wall of text), but I notice a few things, without fail, whenever this topic comes up.
1) The advocates for all of these restrictions on data are incapable of doing so without resorting to flawed arguments, if not outright scaremongering.
A couple selected pieces from this article:
* "If you've ever wondered why Facebook is such a joyless place.."
Can't say I have. Perhaps your Facebook interactions are all dour and joyless because the people you interact with are dour and joyless online? In any case, it's hardly proper to speak this opinion as if it were fact.
* Comparison of ad targeting data to the "pink files" collected for the express purpose of destroying LGBTs, or data collected by various secret police.
Why this is problematic is left as an exercise for the reader.
I'm going to coin a phrase here. You know "reductio ad absurdum"? I'm going to call this "reductio ad missionem malum" - reduction to the worst case scenario. A close relative of the slippery slope.
In this case, the thesis appears to be "Lots of data is collected, therefore burn it all to the ground because it can be misused by the bad guys with guns."
2) Their arguments are not followed to their logical conclusion.
Much hand wringing is done (not by the author necessarily, but in general) about the world when everyone's "youthful indiscretions" and "every mistake" are available online, permanently, for the world to see. Fast forward a decade or so after that line is crossed. What happens when everyone has dirt on everyone? Does that not greatly lessen this impact? It's pretty hard for the guys in suits and dark glasses to blackmail you for something when that information is already out there.
It would be a type of "post-privacy" society, in other words. It is fundamentally different from what we have now, where we have a public personality and a private personality. This carries some positives, some negatives, and I feel it has yet to be discussed in an objective way.
3) Instead of advocating for greater privacy controls that make sense, they instead advocate for measures like the EU's misaimed and "feel good" "right to be forgotten" law.
Look at what the author advocates for:
* "Limit what kind of behavioral data websites can store. When I say behavioral data, I mean the kinds of things computers notice about you in passing—your search history, what you click on, what cell tower you're using."
I for one GREATLY LOOK FORWARD</s> to the day when bureaucrats tell me how my nginx access logs must be formatted and stored (after all, they contain, fairly explicitly "what you click on"). I also look forward with the same enthusiasm to how such a thing will ever be enforced and to find out how much money will be allocated to this particular measure.
I think this is approaching the problem from the wrong angle.
The author says that this is an implementation problem. I, for one, do not want that implementation decided by people who don't understand how technology works. Unfortunately, that seems to be the case whenever you have tech-by-legislative-diktat.
Let me give you an example by way of the next item:
* "Enforce the right to delete. I should be able to delete my account and leave no trace in your system, modulo some reasonable allowance for backups."
Remember how I said the EU law was misaimed and "feel good"? A case where this would do more harm than good: Hacker News. Or indeed any other discussion forum or mailing list archive. Imagine a prolific and quality contributor here, like such as tpacek or even PG. Now imagine that for whatever reason, one of these people want to be "forgotten" and invoke this law.
Imagine what this would do to every single thread that person has ever participated in. Context would be utterly annihilated. This would eviscerate, in the most disgusting sense of the word, most any discussion forum.
I came up with this edge case in less than 60 seconds of thought, and I don't even begin to rank on the list of smartest people on HN. If I can locate such a problem with so little effort, that means both that the people who wrote this law don't know what the fuck they're on about, and it also means that worse edge cases probably exist.
I would say that the legislation needs to target behavior, not tech. Ensuring that private data remains so even after mergers, acquisitions, etc? Excellent. Penalties on companies that misstep? Great idea. Ensuring that government types have to go through the full judicial processes (none of this secret-court-rubber-stamp malarky) to access this data? Awesome!
Making me destroy my website because someone wants to disappear themselves? Less so.
The author is right in the diagnosis, but as you showed, wrong in his prognosis.
It's a serious problem and getting worse. I don't agree that when everyone has dirt on everyone it all just nets to zero. Rather, that would be a sick society. Sure, one ought to reserve judgement, but in practice people usually crave judgement. For better or worse, we are categorising beasts.
My alternative prognosis is much, much more data. Instead of unenforceable rules, I propose digital chaff. When everone has near infinite information on them from many and varied sources, if nearly all of it is bullshit only those already in the know can discern the truth and even then with rapidly diminishing confidence levels. Such chaff would poison many business models so it'd be a disruptive change. My proposal gets to the heart of the author's concern about the disparity between memory and storage, which I share.
One thing: this guy says he couldn't figure out how to block YouTube ads. Ridiculous. It was years before I learned they even had any. Adblock Plus or Adblock Edge both fully block them if you have EasyList (the default).
{kind=link}
Although I disagree with the idea of regulating how long behavioral data is saved. Not all behavioral data is sensitive. Rather we should consider fully disclosing to users either how long their data will be saved or what data has been collected on them or both. Any other regulations may be too burdensome to the startup.
=== Examples ===
His suggestion that all behavioral data be deleted after a certain period of time means every little piece of data collected must also have a timestamp. Inflating databases and costing money.
A program must be written that seeks out timestamped data ready to expire and delete it.
If the deleted data is connected with other pieces of data or reports elsewhere we're going to run into complex problems.
These obligations must be handed down from company to company during acquisitions. A company selling data about to expire will get acquired for a lot less than a company with fresh data. This may in turn cause a series of unforseen consequences in the acquisition market.
=== Solution ===
Rather than controlling and manipulating what can and cannot be done, it may be best to just create transparent policies and let the free market converse its way towards a compromise.