Okay I think I can clarify this:
Electrons trapped in the gate (when storing a 0) come from the substrate. The substrate is connected to ground, and the “lost” electrons are replenished. So yes, net chip weight grows when 0s are written.
However, weight relative to what? All 0s on a chip will be heavier (the heaviest). All 1s would be the lightest. 50/50 1s and 0s would be the middle, which is where I’d expect generic “data” to fall.
So glad someone else also knew about this connection :) Details about Denver are pretty minimal, but this talk at Stanford is one of the most detailed I’ve been able to find for those interested. It’s fascinating stuff with lots of similarities to how Transmeta operated: https://youtu.be/oEuXA0_9feM?si=WXuBDzCXMM4_5YhA
There was a Hot Chips presentation by them that also gave some good details. Unlike the original Transmeta design they first ran code natively and only recompiled the hot spots.
This is a pretty disappointing article with some very questionable examples.
The Imagination Technology example in particular is poor since they were a supplier of intellectual property, not physical goods. So Apple’s usage of them as a supplier had limited bearing on the firm’s other customers or lack thereof. Similarly, the ban of Apple Watches over IP theft has nothing to do with the supply chain issues that the authors attempted to outline.
The thesis is also all over the place. The title indicates the problem is semiconductors, but then lots of the arguments have to do with suppliers outside of semiconductors. If Apple’s reliance on TSMC is the big problem, then why isn’t even mentioned that TSMC is the only competitive fab on cutting edge nodes?
Lastly, the overarching theme is severely misguided. All of these supply chain dealings are as old as semiconductors themselves. When the industry moved towards targeting consumer electronics in the 70s, semiconductor manufacturing moved out of the US long before Apple was relevant. And if Apple weren’t a powerhouse of consumer electronics today, other companies would be doing the same things. It’s just part of the nature of trying to manufacture and sell mass market electronics.
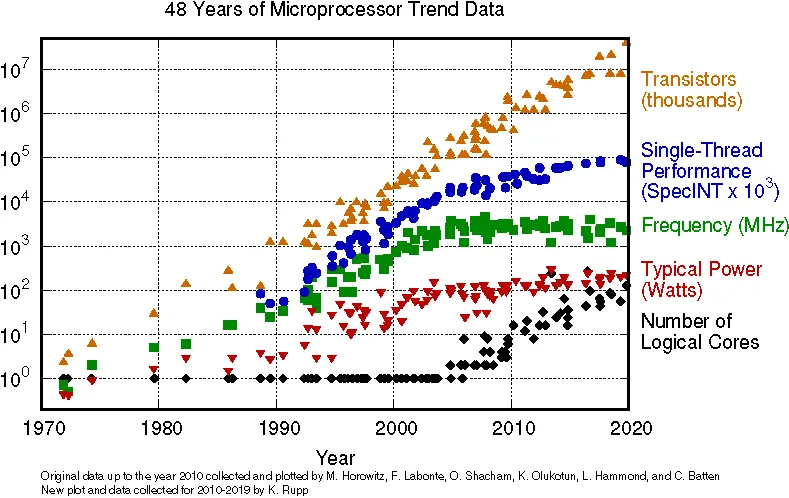
I'll give you an alternate take: the compute power available to EDA software has been roughly scaling at the same rate as transistors on a die. So the complexity of the problem relative to compute power available has remained somewhat constant. So standard cell design remains an efficient method of reducing complexity of the problems EDA tools have to solve.
That's an interesting thought. However, it assumes that the problem scales with the number of transistors, i.e. O(N). I expect that the complexity of place and route algorithms is worse than O(N), which means the algorithms will fall behind as the number of transistors increases. (Technically, the algorithms are NP-complete so you're doomed, but what matters is the complexity of the heuristics.)
It's worse than that, isn't it? Not only are the algorithms presumably super linear, the transistor count has been increasing exponentially, but the compute power per transistor has been decreasing over time. See e.g. [1].
Although I suppose if the problem is embarrassingly parallel, the SpecINT x #cores curves might just about reach the #transistors curve.
yeah, that plots single-threaded performance, not total compute power. the point it's making is that now those transistors are going to parallelism rather than to single-threaded performance, and also the compute power per transistor stopped increasing around 02007 with the end of dennard scaling
your problem doesn't have to be ep to scale to 10² cores
i suspect it's true that compute power per transistor is dropping because thermal limits require dark silicon, but that plot doesn't show it
Tesla has a path to economies of scale: they already announced that if Dojo works as expected they'll make it available to others as an AWS-style service.
Which is brilliant: they might end up making money on this.
AI is clearly here to stay. The demand for AI training will clearly explode in the future.
Running training in-house is not easy or cheap. You don't just plug in 1000 NVIDIA GPUs. You need massive up-front payment for GPUs and you're basically running your own extremely energy hungry datacenter .
Tesla might built and operate massive datacenters. They'll use as much as they need for internal needs and sell the remaining capacity to others.
This might take 5 years but the path to do it is clear.
I don’t see how they’re going to commercialise this as a cloud compute service.
For one, they’ve built a chip that operates in a fundamentally different way to other chips. So any other company that wanted to use it would have to invest a considerable amount of resources in building up the institutional knowledge to use it effectively.
Additionally, the lack of virtual memory and multi-tasking support renders it pretty much impossible to divide up compute between multiple customers. So, commercialising this would require customers renting out the whole unit, which is contrary to how cloud computing usually works.
Are there companies out there that have the capital and use cases necessary to fit into Dojo Cloud? Maybe, though not one I’ve worked for. Would they trust the stable genius currently heading up Tesla enough to make such an investment? Perhaps, but I wouldn’t, but what do I know?
> Additionally, the lack of virtual memory and multi-tasking support renders it pretty much impossible to divide up compute between multiple customers. So, commercialising this would require customers renting out the whole unit, which is contrary to how cloud computing usually works.
Only if you want to subdivide the compute on each dojo chip. You can still provide multi-tenant, support by allocating entire dojo chips to a single customer at a time. Even traditional time division multi-tasking is possible as long as you’re happy to accept multi-second long time slices. Then the overhead of clearing an entire dojo chip (or batch of chips), and setting up a new application, isn’t too high.
If you’re doing AI workloads, then none of the above are an issue. Training a large net takes days to weeks of continuous, single task computation. So selling dojo access in whole 1 hour blocks is a perfectly reasonable thing to do.
Reliability is an important factor here, and I don't mean technology.
Things don't look so good for everything that has to do with Musk. Today like this, tomorrow like that
>Things don't look so good for everything that has to do with Musk. Today like this, tomorrow like that
Such as? Except for FSD, his record is unmatched AFAIK when you take into account the novelty / complexity / difficulty.
One example, and certainly his main achievement: he said Tesla would sell and produce half a million cars by 2020, back in early 2014, and they hit that number with a 93.6% precision. https://youtu.be/BwUuo6e10AM?t=156
Some of Musk's stuff is great - other stuff isn't.
SpaceX? Great. Starlink? Sounds neat. Tesla? Pioneered electric cars with respectable performance and range.
But on the other hand, where's the hyperloop? Where's the affordable tunnelling? Where's the $35k Tesla - not available for order on the website, that's for sure. Where's the miniature submarine for rescuing children trapped in caves? Why has my buddy in Europe been waiting over a year for his powerwall to be delivered? Why are these norwegian tesla owners on hunger strike? Where's the full self driving, with taxi service? Why on earth would anyone want to buy Twitter?
Makes it very difficult to know which of Musk's statements are just spitballing, which are unrealistic timescale guesses and which can be relied on.
Getting any serious project architecturally 'locked in' to a special type of CPU you can only get from Tesla would be a bold move.
It's simple, SpaceX, Tesla and Starlink are evolutions of existing technology.
FSD, Hyperloop and such would be revolution like out of a Sci-Fi movie.
They fail all because Musk like would like to have those things but in reality these things are much more complicated as he says.
yes, you still write checks to pay online and rocket boosters to this day are single use $100M pieces of hardware that we throw away into the ocean after each use.
seriously. musk is shady and weird, more so in the last couple of years, but come on.
It's about the perception of Musk.
He built some successful companies but he is not Tony Stark as people tend him to see.
He is a salesman not an genius inventor.
Don't expect FSD in the near future and don't expect a Mars colony.
FSD, especially the way he was describing it, was a blunder. the Mars city is a pipe dream... but I absolutely understand why it makes people follow him - he's the only one who set out to build a private space company with the purpose to actually get to Mars, with the side effect of completely uprooting the space launch industry. the achievements are undeniable, but it's the vision that makes the perception be so surprisingly good still. there's literally nobody else who says things like that and has the means to even try.
I assume you never actually built any cloud infrastructure yourself. Plus Tesla (aka) Elon, well, say a lot of stuff, not always necessarily correct.
Internal research product is super far from any actual production usage. Especially if you go against some established paradigms, that require enormous amount of effort (more than developing silicon) to build tolling around, so people can design, program, debug, monitor it.
But that’s internal usage. Cloud is a totally different ballgame. You have to deal with thousands more requirements (and you cannot generally tell customer to do something else instead, as you can with internal teams). And customers that have operating procedures totally different from yours, 0 access to your internal knowledge and infinite less tolerance for BS answers (as you are paying customer, not a someone on the same boat).
Building cloud is extremely hard, and there’s a reason why Google is still losing money on it.
Plus, let’s even say that your 5 year estimate is correct, Dojo is amazing and the future of tech and they may have viable product by then. Do you think that Nvidia wont advance their AI offering by then? Google TPU will stop being developed? Or will Tesla continue investing to churn new generation of Dojo every year?
> You have to deal with thousands more requirements (and you cannot generally tell customer to do something else instead, as you can with internal teams).
You can. AWS started with S3 when everyone was using databases. As long as it’s cheaper than its competition, single use-case (you won’t serve a website on these) has a market.
> You can. AWS started with S3 when everyone was using databases.
AWS staryed when there was no competitor.
Google started with a ton of world-class expertise when AWS was up and running and while operating already a colossal network of server farms using special-purpose, which Tesla has none of which, and after all these years barely got a 10% market share.
What they want is a training engine that is cheaper than whatever AWS or Google (or anyone else) can offer. If I can point my PyTorch to it instead of an AWS GPU for less money, why not?
> What they want is a training engine that is cheaper than whatever AWS or Google (or anyone else) can offer.
Bold assumption, considering Tesla's hardware does not exist, the market is limited and Google has already years of providing machine learning services with special purpose hardware.
Their hardware. They have, at best, 1 supercomputer (though it's not actually clear if they have more than some Dojo prototypes to me). That does not a cloud make.
Ah yes, I see that now. But assuming they make the computer, they could also lease it to one or more cloud providers as a service. They don't necessarily have to build the whole thing.
> Tesla has a path to economies of scale: they already announced that if Dojo works as expected they'll make it available to others as an AWS-style service.
"If we manage to put together a working processor, supporting hardware, OS, and possibly ad-hoc programming language, our next step is to also develop a bunch of web services to provide cloud hosting services."
Not very credible. As if the key to offer competing cloud hosting services is developing the whole hardware and software stack.
And network infrastructure, isolation between customers, scheduling hardware allocation, etc etc running one own data enter is quite different than inviting all sort of third parties in.
> Yeah, but it’s not like this is rocket science or anything.
The key difference between this goal and SpaceX is that Elon Musk bought a private space company that already had the know-how and the market presence in a market with virtually no competitor.
In this case, Tesla is posting wild claims about developing the whole vertical integration of the whole tech stack barely over mining semiconductor raw materials, with which goal? Competing with the likes of AWS, Google, and Microsoft, on a very niche market?
Digging holes in the ground is hardly rocket science as well.
Ever since Elon became the world's richest man people like this have showed up. I don't know if they have been misinformed or if they just want to say negative things about billionaires. But the early history of SpaceX is very well documented in the book liftoff if anyone wants to know the truth.
You say that Tesla might do this for others, AWS style.
Then talk about the upfront in house costs of setting up for GPU ops. But ignore that if an AWS style model works for you, well, AWS is already capable of giving it to you in GPUs.
They aren't going after economies. If you look closely at their design choices, they are building a pure scale-out vector machine unlike anything else currently on the market. I'm guessing they expect it to be head & shoulders ahead for their inhouse workload.
Performance is agnostic of ISA. Apple's custom designed cores do indeed have a massive performance/Watt advantage over x86 based designs and happen to be using ARM. However, it's not impossible for an x86 CPU to be designed in a similar way. It does, however, get more difficult to do so due to x86's variable length instruction encoding, to which ARM does not have.
x86’s instruction decoder suffers from its inability to parallelize some things. Because instructions have no fixed boundary,[a] something has to process the bytes sequentially. Even if they can be read from memory in massive amounts, something still has to sit there going byte by byte to find the boundaries.
The good news is, once those boundaries are found, uops can be generated. But that ~5% or so of die space is always running full tilt (provided there’s no pipeline stalls).
I’m sure Intel and AMD have put a massive amount of work into theirs to make it as quick as possible,[b] but it’s still ultimately a sequential operation.
With RISC-like architectures like ARM and RISC-V, you don’t need that boundary detector. Just feed the 2 or 4 bytes straight into the decoders.
[a]: Unlike ARM and RISC-V which have fixed 2 or 4 byte encodings (depending on processor mode), x86’s instructions can be anywhere from 1 through 15 bytes.
[b]: Take the EVEX prefix for example. It is always 4 bytes long with the first one being 0x62. So, once you see that 0x62 byte after the optional “legacy prefixes”, you can skip 3 bytes and go to the opcode. But then you need to decode that opcode to see if it has a ModR/M byte, decode that (partially) to see if there’s an SIB byte, decode that to see if there’s a displacement (of 1, 2, or 4 bytes), etc. And then, don’t forget about the immediate (which can be 1, 2, 4, or (in one case of MOV) 8 bytes).
Not that I’m aware of. The decoding of an instruction is complicated and also dependent on the current operating mode and a few other things. So, for an OS to pass those lengths before hand, it’d have to know everything about the current state of the processor at that instruction. For example, in 16 and 32 bit modes, opcodes 0x40 through 0x4F are single byte INC and DEC (one for each register). In 64 bit mode, those are the single byte REX prefixes; The actual opcode follows. See also: the halting problem.
As for why it became an issue, instruction sets need to be designed from the beginning to be forward expandable. Intel has historically not done that with x86. Take AVX for example. Originally, it was just 128 bit (XMM) vectors encoded as an opcode with various prefix bytes being used in ways they weren’t intended. Later, 256 bit vectors were needed. So they made the VEX prefix. But it only had 1 bit for vector length. This allowed 128 bit (XMM) and 256 bit (YMM) vectors, but nothing else. So when AVX-512 came along, Intel had to ditch it and create the EVEX prefix and allow both to be used. But EVEX only has 2 bits for vector length. So, should something past AVX-512 come out (AVX-768 or AVX-1024?), it’ll probably use the reserved bit pattern 11, and they’ll be stuck again if they want to go past that.
For an example of this being done right, ForwardCom[0] (started by the great Agner Fog) took the “forward compatibility” (hence the name) issue into mind and used 2 bits to signal the instruction length. It’ll probably never reach silicon, but it and RISC-V (which is in silicon form) are good examples of attempting to keep things forward compatible.
> Not that I’m aware of. The decoding of an instruction is complicated and also dependent on the current operating mode and a few other things. So, for an OS to pass those lengths before hand, it’d have to know everything about the current state of the processor at that instruction
The compiler would know the instruction boundaries. It could store that information in a read-only section in the executable. The OS would then just pass that section to the CPU somehow.
I don't think there is anything impossible about this. Would there be sufficient performance benefit to justify the added complexity? I don't know, quite possibly not.
I'm not sure why it would be. If the boundary information were wrong, the CPU instruction decode would fail, but that should just be an invalid instruction exception, which operating systems already know how to handle.
"Performance is agnostic of ISA" is too strong a statement. The variable length instruction encoding is a significant performance disadvantage, as is the strict memory ordering requirement of X86/X64.
X64 decoders are indeed only ~5% of the die on a modern CPU, but it's 5% that is always at 100% utilization. That's a non-trivial amount of extra power. X64 decode parallelism is also limited. I've heard four instructions at once as a magic number beyond which it becomes really hard. This is why hyperthreading (SMT) is so common on X64 chips. It's a "cheat" to keep the pipeline full by decoding two different streams in parallel (allowing 8X parallelism). SMT isn't free though. It drags in a lot of complexity at the register file, pipeline, and scheduler levels, and is a bit of a security minefield due to spectre-style attacks. All that complexity adds more overhead and therefore more power consumption as well as taking up die space that could be used for more cores, wider cores, more cache, etc.
ARM is just a lot easier to optimize and crank up performance than X86. The M1 apparently has 8X wide instruction decode, and with fixed length instructions it would be trivial to take it to 16X or 32X if there was benefit to that. I could definitely imagine something like a 16X wide ARM64 core at 3nm capable of achieving up to 16X instruction level parallelism as well as supporting really wide vector operations at really high throughput. Put like 16 of those on a die and we're really far beyond X64 performance in every category.
This is also why SMT/hyperthreading doesn't really exist in the ARM world. There's less to be gained from it. Better to have a simpler core and more of them.
IMHO X86/X64 has hit a performance wall at least in terms of power/performance, and this time it might be insurmountable due to variable length instructions and associated overhead. It matters in the data center as well as for mobile and laptops. There's a reason AWS is pricing to steer people toward Graviton: it costs less to run. Power is the largest component of most data center costs.
While it’s absolutely true that fixed width instructions make parallel decoding vastly easier, there’s a cost in terms of binary footprint size. x86 generally has an advantage in instruction cache and TLB performance for this reason, which can be significant depending on the workload.
Not true. This is a common myth that comes from some old Linus posts in the 32-bit Pentium 4 days and still won't die. I've done comparisons to test this. Compare sizes of modern x86-64 Linux binaries to their counterparts on AArch64. You'll find that they're extremely close.
The biggest problem is all the REX prefixes. The inefficient encoding of registers in x86-64 squandered all the advantages that x86 had.
> > x86 generally has an advantage [empahsis added, not "x86-64"]
Obviously if you take the worst of both worlds (bloated and variable-width instructions), you can squander that advantage, but the advantage is in fact real.
Is this still really relevant? I can understood that it can be a problem 20 years ago, but with current processor with huge L1 cache and memory bandwidth, I am starting to think that 4 bytes (or variable 4/8 bytes) is not a bad tradeoff for density Vs superscalar.
The L1 size is yet another place where the x86 legacy hinders things. To avoid aliasing in a virtually indexed L1 cache (which is what you want for performance in a L1 cache, since a physically indexed cache would have to wait for the TLB lookup), the size of each way is limited to the page size, which on x86 is 4096 bytes. To get a 64 KiB L1 cache, it would have to be a 16-way cache, and increasing that too much makes the cache slower and more power-hungry. It's no wonder Apple decided to use a 16 KiB page size instead of a 4 KiB page size; a 64 KiB VIPT L1 cache with 16 KiB page size needs only 4 ways.
For the L1 instruction cache, aliasing shouldn't be a problem (since it's never written to), but this is once again another place where the x86 legacy hinders things: instead of requiring an explicit instruction to invalidate a virtual address in the instruction cache, it's implicitly invalidated when writing to that address.
Wow. Didn't know that. That should more than compensate for a very slight increase in code size for ARM64 vs X64.
When I use M1, AWS Graviton, or even older Cavium ThunderX chips I can't help but think that X86 is on its way out. The advantage is something you can subjectively see and feel. It's obvious, especially when it comes to power consumption.
Process node has something to do with it, but it's not the whole story. I'm typing on a 10nm Ice Lake MacBook Air and while this chip is better than older 14nm Intel laptops it's still just shockingly crushed by the M1 on every metric. 10nm -> 5nm is not enough to explain that, especially since apparently Intel is more conservative with its numbering and Intel 10nm is more comparable to TSMC 7nm. So it's more like TSMC 7nm vs TSMC 5nm, which is not a large enough gap to account for what seems to be at least 1.5X better performance and 3X better power efficiency.
Some of the X86/X64 apologists remind me of old school aerospace companies dissing not only SpaceX and Blue Origin but the whole idea of reusable rockets, trying to convince us that there's little economic advantage in reusing a $100M rocket stage that consumes ~$100-200K in fuel per launch.
"That's not much of a meteorite. It's no big deal." - Dinosaurs
Agnostic is a little strong, although it is true that M1 is extremely wide especially for a laptop chip, and wide in ways beyond the decoder which could be applied to an X86 part.
Ultimately these discussions are quite hard because AMD aren't on exactly the same density, and Intel are quite a way behind at the moment.
That's because you're locked into the x86 paradigm. Look at the leaps and bounds Apple is making with performance/Watt by moving away from x86. This is the cost of legacy.
Architecture emulation like QEMU provides is commonly used, just a matter of how much investment is made into backwards compatibility by those who build your operating system/platform.
Apple works hard to break backwards compatibility every few years, while other operating systems will happily run software from decades ago as they care and invest in not breaking userspace.
Apple really likes being on the bleeding edge of computers, and it often comes at the cost of older programs and features being killed off in that process.
While I agree the issue is most certainly real, I feel that Apple Silicon is the scapegoat. Computing platforms need to evolve in order to progress, and sometimes the burden lies on developers to keep up. I think this is more of a story about legacy software compatibility and lack of open source solutions.
One of the nice things for users on MacOS is devs are forced to keep up and use the latest standards pretty quickly so everything just works mostly as long as you aren't using an unmaintained tool or updating OS on day one. On Linux I have to use Wayland to properly support different screen DPIs but then a bunch of software hasn't updated to use the new apis because they can just tell the user to revert to X.
Which is, in turn, merely an abstraction over the actual quantum physics that governs what's really happening on the silicon. And quantum physics might itself one day may be found to be a higher level abstraction of what's really really going on, as happened with Newtonian physics before it.
It's abstractions all the way down. I don't know why they're so maligned by programmers, they're the only way any work gets done.
heh and it's even worse than that, because near the quantum level, we're mainly finding reflections of our own psychology, psyche and societal norms.
This is why saying sth is "not how the machine works" is a fallacy of black and white thinking and not useful unless one is ready to be very specific abt how it resembles the machine and doesn't.
wrt C, the smartest thing to do is use it wisely and avoid dragons, the same way we e.g. use chemistry to make useful products without performing operations in unstable environments. And surround it with an appropriate layer of cultural expectations - keeping humans in the loop. You don't just do what the computer tells you, you use it to help you make judgments, but ultimately take responsibility yourself.
One can see this in Rust's efforts to not only develop a language, but a conscious culture around it. This will be successful until, like a 51% attack, it is outmaneuvered.
I don't think anyone suggests using C as an alternative for microarchitecture classes. C still remains one of the best ways to access hardware relative to other software languages. No language is "how computers work" unless you're writing Verilog, but C is the closest to the metal relative to other software paradigms while still being more convenient than assembly.
{kind=link}
However, weight relative to what? All 0s on a chip will be heavier (the heaviest). All 1s would be the lightest. 50/50 1s and 0s would be the middle, which is where I’d expect generic “data” to fall.